
Amazon Rekognitionのカスタムモデレーションを利用してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部 機械学習チームの鈴木です。
2023年10月に登場したAmazon Rekognitionのカスタムモデレーション機能ですが、以前から関心があり、いよいよ試してみました。
以下のブログで紹介していました。
なお、Amazon Web Services ブログで非常に分かりやすい記事が公開されており、こちらもご参照ください。
本記事も、こちらのブログを参考にしつつ、実際に試してみてどんな動線になっていたかなど中心にご紹介できればと思います。
コンテンツモデレーションについて
コンテンツモデレーションとは
ユーザーがコンテンツを作成できるウェブサイトで、無関係・わいせつ・違法・有害・侮辱的な投稿を検出する工程です。
問題のあるコンテンツに対して削除または警告ラベルを適用し、ユーザーが自分でコンテンツをブロックおよびフィルタリングできるようにすることが目的となります。
例えば、動画配信サービスで再生開始時に「たばこ」とか「飲酒」とか警告ラベルが出るのがよく目にするものだと思います。
AWSでコンテンツモデレーションをするには
コンテンツモデレーション自体は画像や動画に限らず、テキストなどコンテンツ全般に対して行えるものになります。
AWSでコンテンツモデレーションをする際の選択肢としては、私が把握している範囲だと以下があると思います。
- 警告ラベルの対象となる状況の画像・動画
- Amazon Rekognitionのコンテンツモデレーションで対応可能
- キャラクターやロゴなど著作権侵害の検出
- 特定の対象であればAmazon Rekognitionのカスタムラベルで対応可能
- マルチモーダルなLLMによる判定
- 不適切なテキスト
- Amazon Comprehend toxicity detectionによる分析(英語のみ)
- Amazon Translate Masking profane機能による、翻訳対象中の不適切な単語のマスクによる判定
- LLMによる判定
最近はテキストおよびマルチモーダルな入力に対応したLLMが活躍しており、これを使ったより抽象的なコンテンツモデレーションができる可能性が見えてきたことが新しい進展かと思います。
DevelopersIOでも以下のブログでAmazon BedrockからClaude 3.5 Sonnetを使って試してみた例をご紹介しています。
ただしLLMなので、ハルシネーションや再現性は課題として残ります。
Amazon Rekognitionについて
画像認識・動画処理向けのAWSのマネージドサービスです。
以下のように、画像・動画に対して多岐にわたる分析ができます。
- 顔画像のマッチング
- 顔画像の検索
- ラベル検出
- モデレーション(有害性の検出)
- 顔の検出と分析
- 画像中のテキスト検出
- 有名人の認識
- 個人用防護具 (PPE) 検出
- 画像のプロパティ分析
以下の記事では今年の春時点の機能についてほぼ全部紹介しています。(すごい)
Amazon Rekognitionのコンテンツモデレーション
カスタムモデレーションを理解するために重要なため、Amazon Rekognitionのコンテンツモデレーション自体についても少し触れておきます。
コンテンツモデレーション機能により、画像を入力に、その画像に対する警告ラベルをつけることができます。
ラベルは3階層となっており、現在は第3レベルカテゴリ粒度で全34種あります。この階層やラベルは、過去のアップデートを通して改善されてきているものとなります。
例えばアルコールだと以下のような検出ができます。

※画像はいらすとやよりダウンロードして使用しました
ラベルは以下に全量があります。
Amazon Rekognitionのカスタムモデレーション
アダプターを訓練することにより、デフォルトのコンテンツモデレーションをカスタマイズできる機能です。
Amazon Rekognitionのコンソールでも紹介されていますが、以下のような流れになっています。
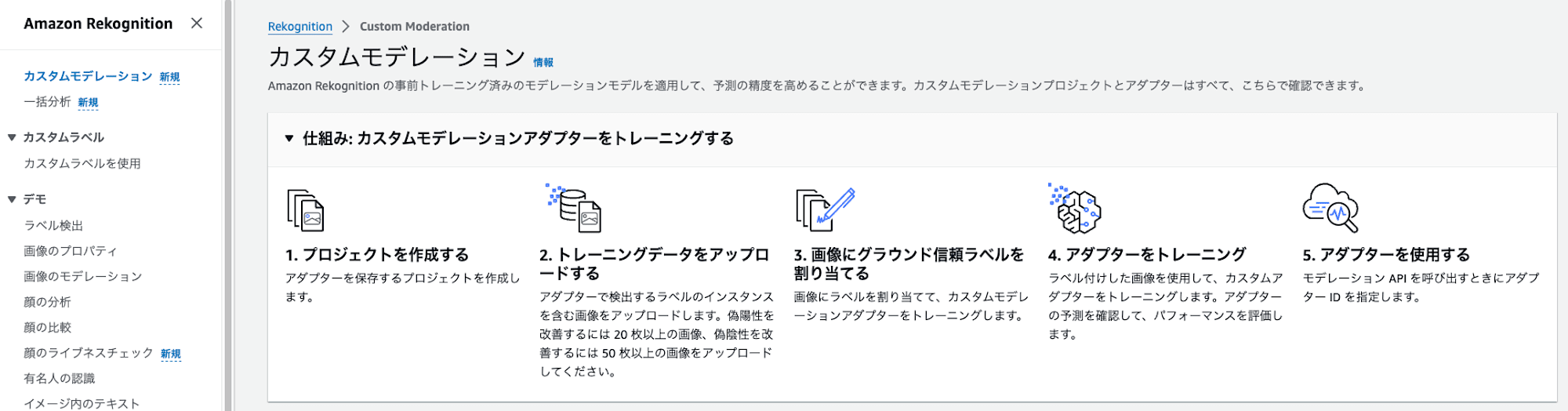
重要なポイントは、新たな不適切なラベルを追加するのではなく、既存のラベルに割り当てられない画像を、既存ラベルに判定できるようにする機能であることです。私も最初勘違いしていましたが、ラベルを追加する機能でないことは留意しておきましょう。
使ってみる
0. 課題設定
今回は以下の課題を解決するモデレーション向けのモデルを作成することとしました。
自社のECサイトで、高級ワインの取引が行われており、配送時に破損するなどトラブルが多発している。
そもそも酒類の取引は認めておらず、アルコールに関するアイキャッチを設定できないようにコンテンツモデレーション機能でブロックしているが、高級ワインを表す画像としてレーズンの画像が使われるケースがあり、知らないうちに販売が続いていた。
レーズンの画像もアルコールとしてラベル付けしたい。
1. データの準備とS3バケットへのアップロード
上記課題を解決するため、データを用意しました。
- トレーニング向け:
- 50枚のレーズンの画像
- 20枚のレーズンに似ているがレーズンではない画像
- テスト向け:
- 20枚のレーズンおよびレーズンに似ているがレーズンではない画像
今回はレーズンは全てアルコール判定したいので、偽陽性サンプルは用意しませんでした。
データセットのベストプラクティスはAmazon Rekognitionのガイドに記載されています。
画像の例は以下になります。



合わせて90枚の画像をS3バケットにアップロードしました。
2. プロジェクトの作成とラベリング
次に、Amazon Rekognitionのコンソールからカスタムモデレーションのプロジェクトを作成しました。
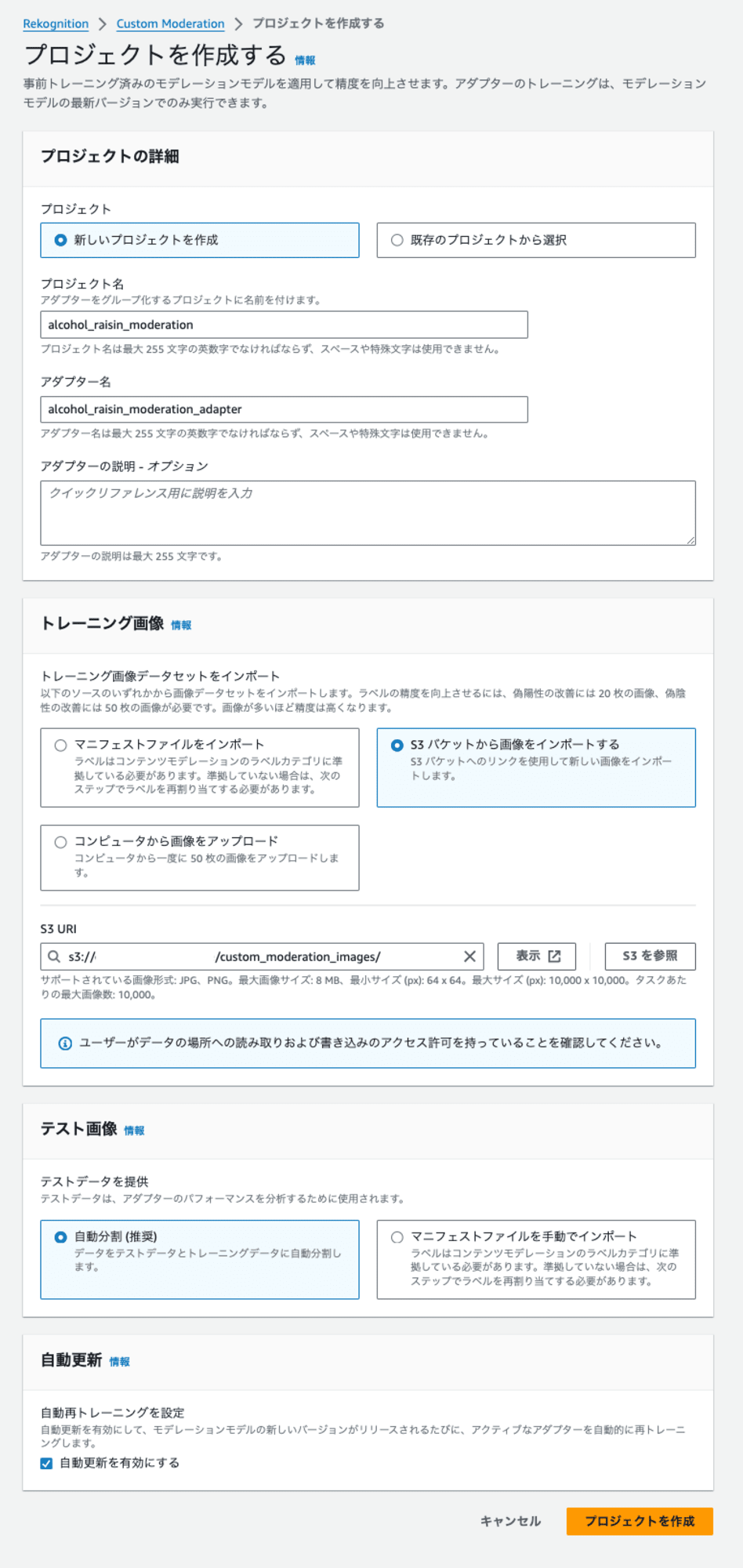
プロジェクト名・アダプター名を入力し、アップロードしたS3バケットの画像からトレーニング画像を読み込むようにしました。
以下のようにラベルを割り当てる画面に遷移するので、ラベルを画像に割り当て、ドラフトを保存しました。
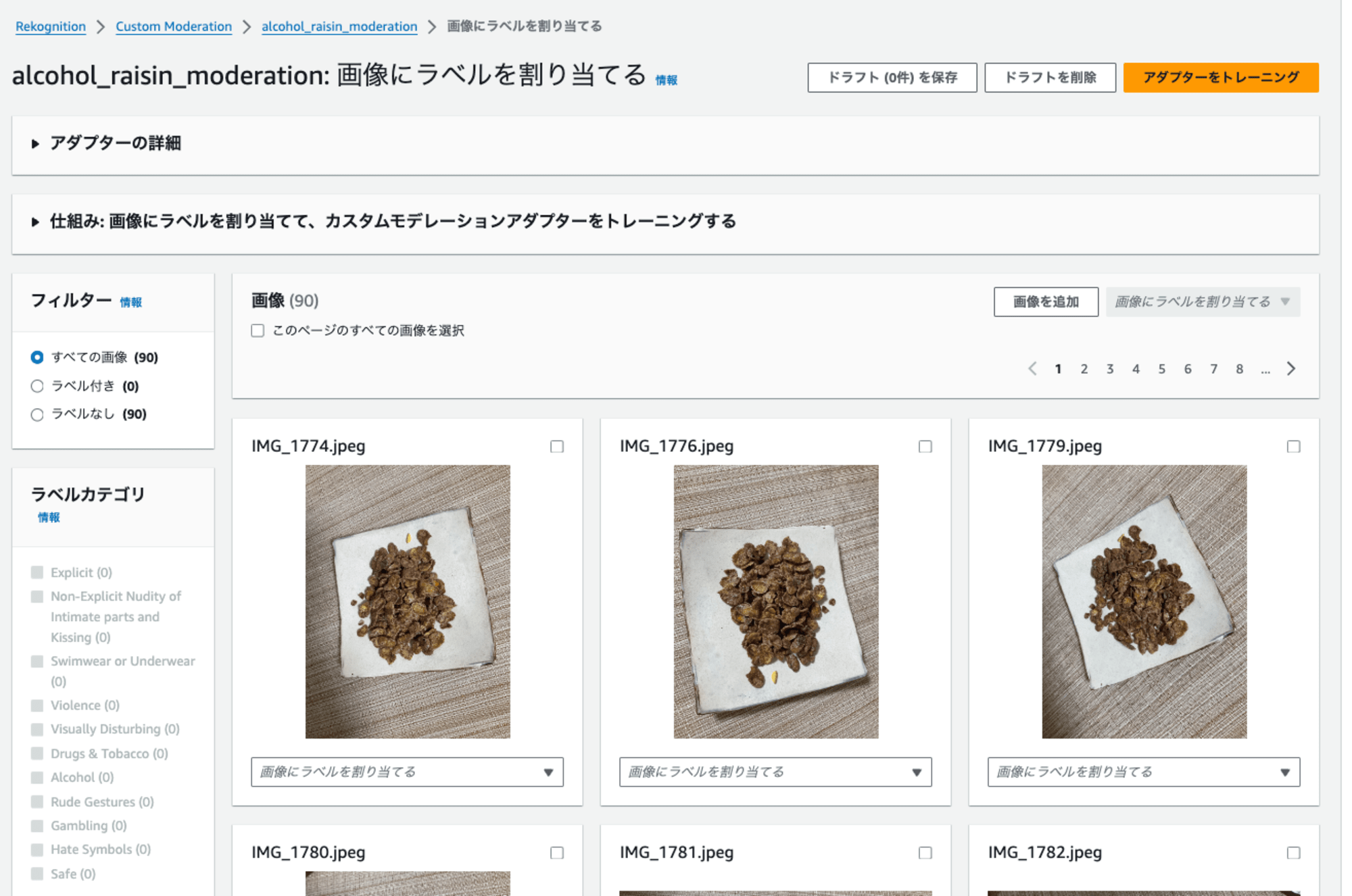
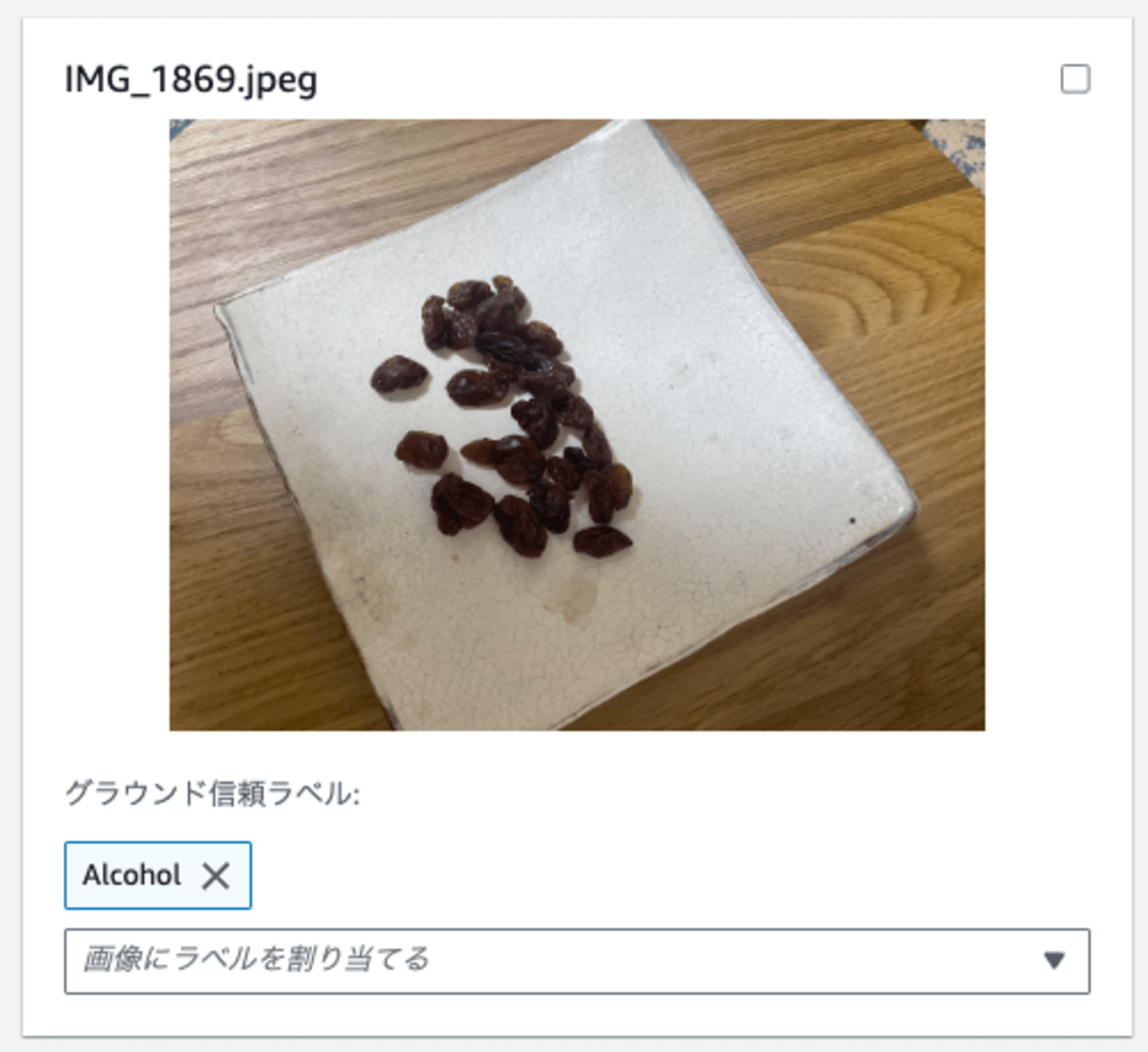
なお、画像はこのページの全ての画像を選択でページ単位で一括選択でき、一気にラベルを割り当てることもできました。ラベルは左下に見えているように、Rekognitionのラベルを割り当てる形となります。今回はレーズンの画像にはAlcoholを、それ以外にはSafeを割り当てました。
3. アダプターのトレーニング
続いてアダプターをトレーニングしました。これはプロジェクト上部のアダプターをトレーニングボタンを押すだけです。トレーニング時のオプションを指定することができます。
トレーニング中です。
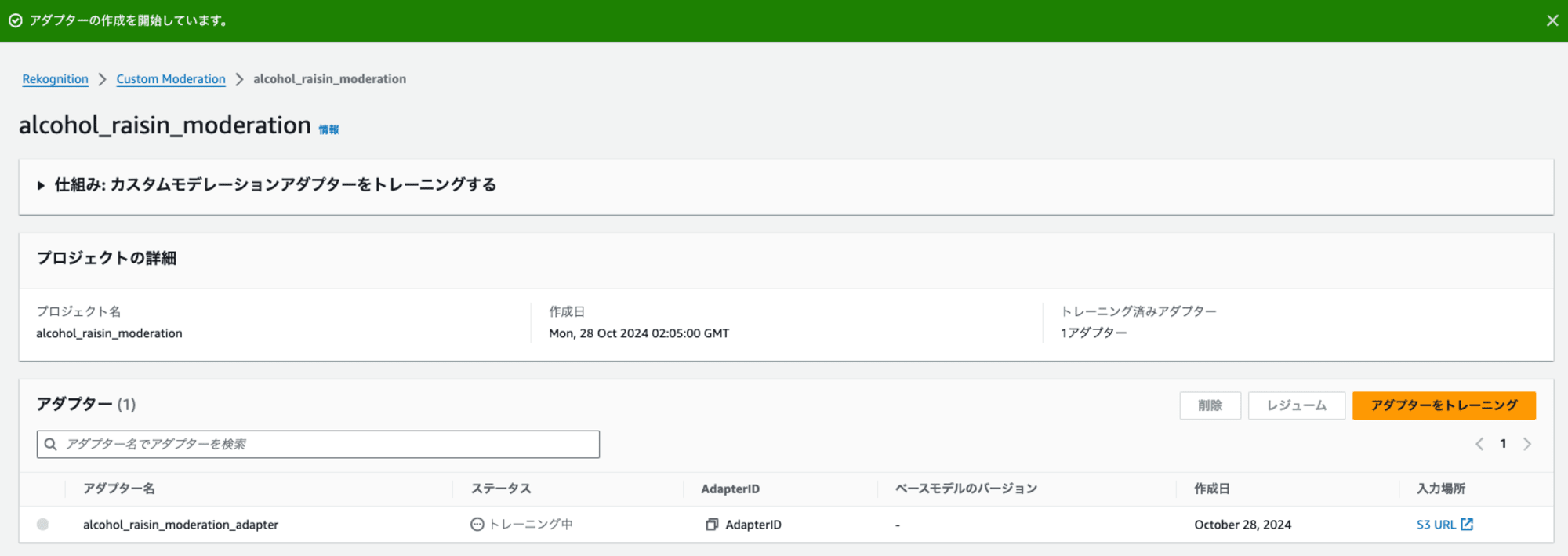
完了するとステータスがトレーニング完了になります。
4. パフォーマンスの確認と実行
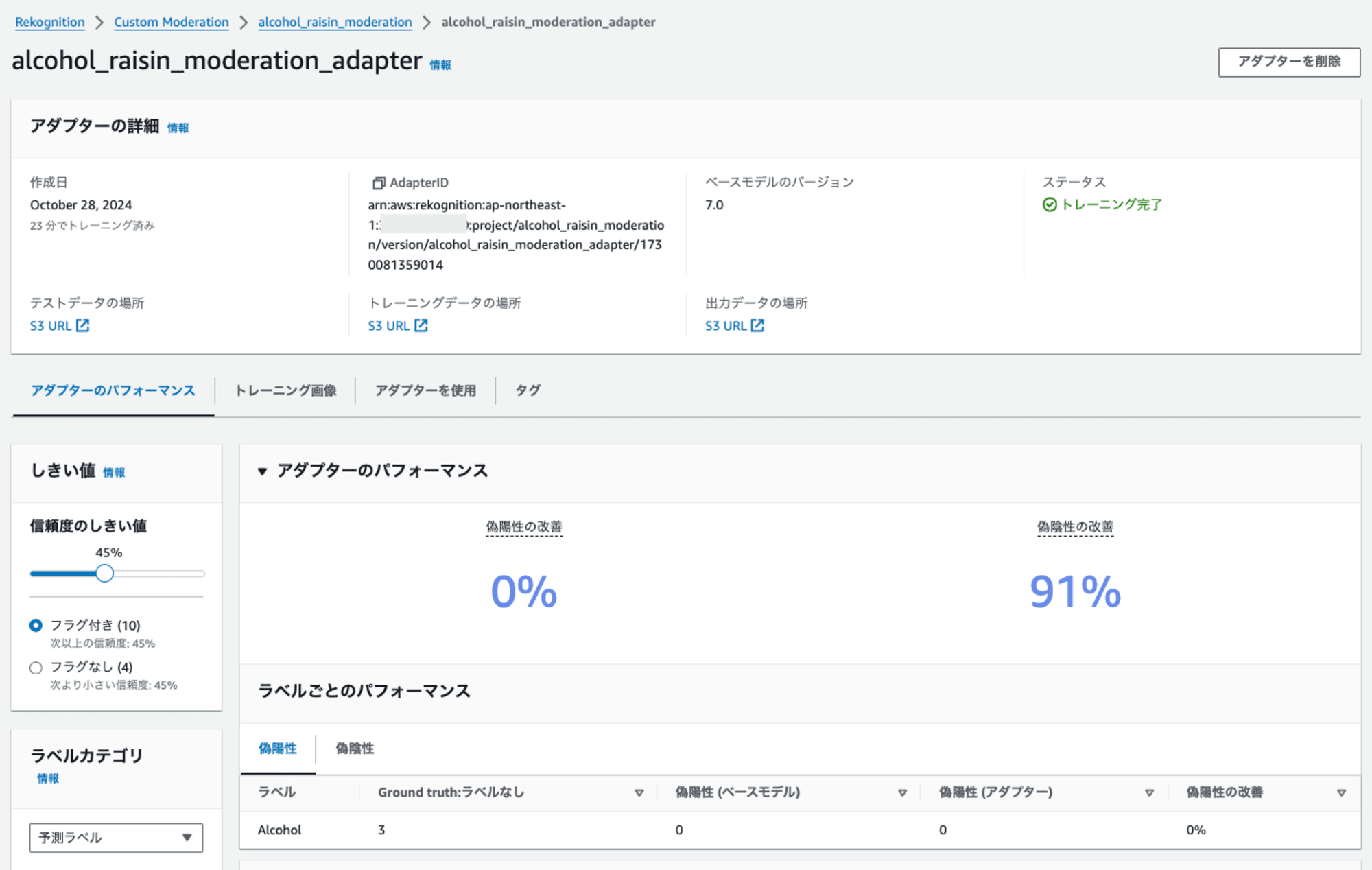
トレーニングが完了したアダプターを選択すると、以下のようにパフォーマンスを確認することができます。特に信頼度のしきい値を調整した際に、テスト画像に対したパフォーマンスが分かるため、推論時にはこのしきい値を使うと良いです。
推論はAWS CLIおよびboto3などから行うことができます。以下のように--min-confidenceでしきい値を指定できました。
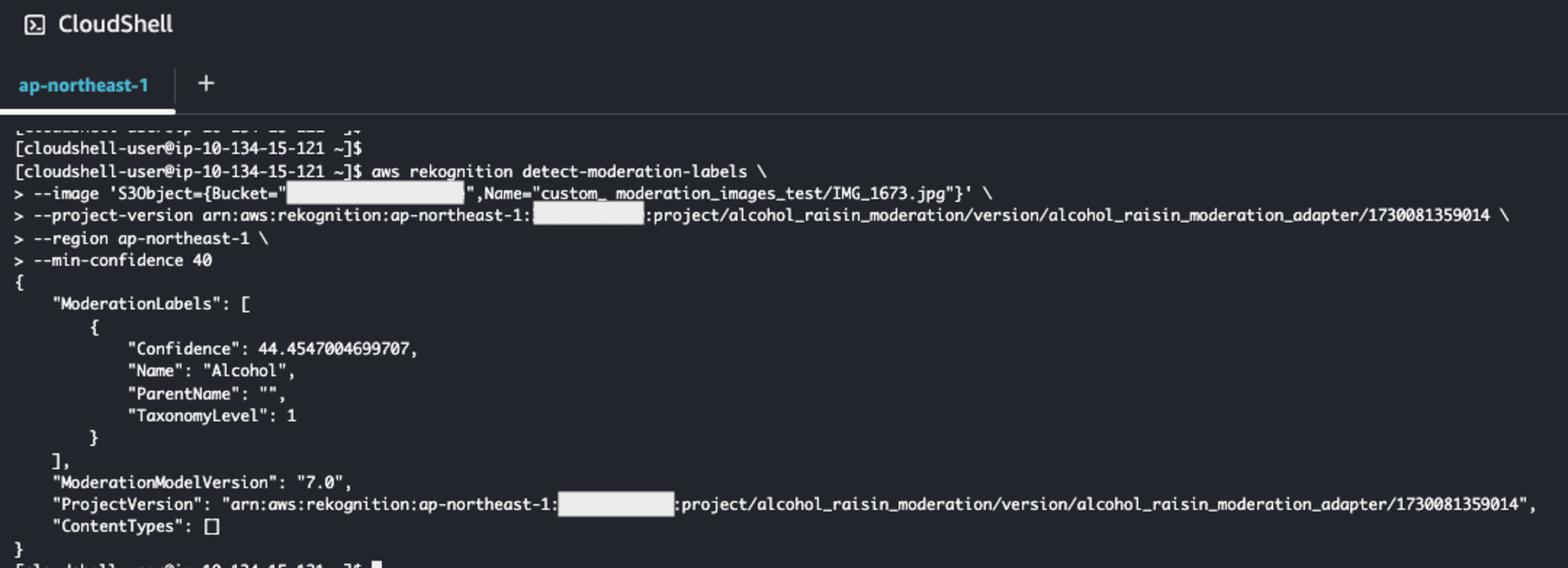
テスト画像はS3バケットに以下の画像をアップロードしておきましたが、確かにアルコールとして判定されていますね!

最後に
Amazon Rekognitionのカスタムモデレーションを利用してみたので動線をご紹介しました。
参考になりましたら幸いです。










